現状の生成AIに対する僕の考え〜岸田メル先生のスペースによせて〜

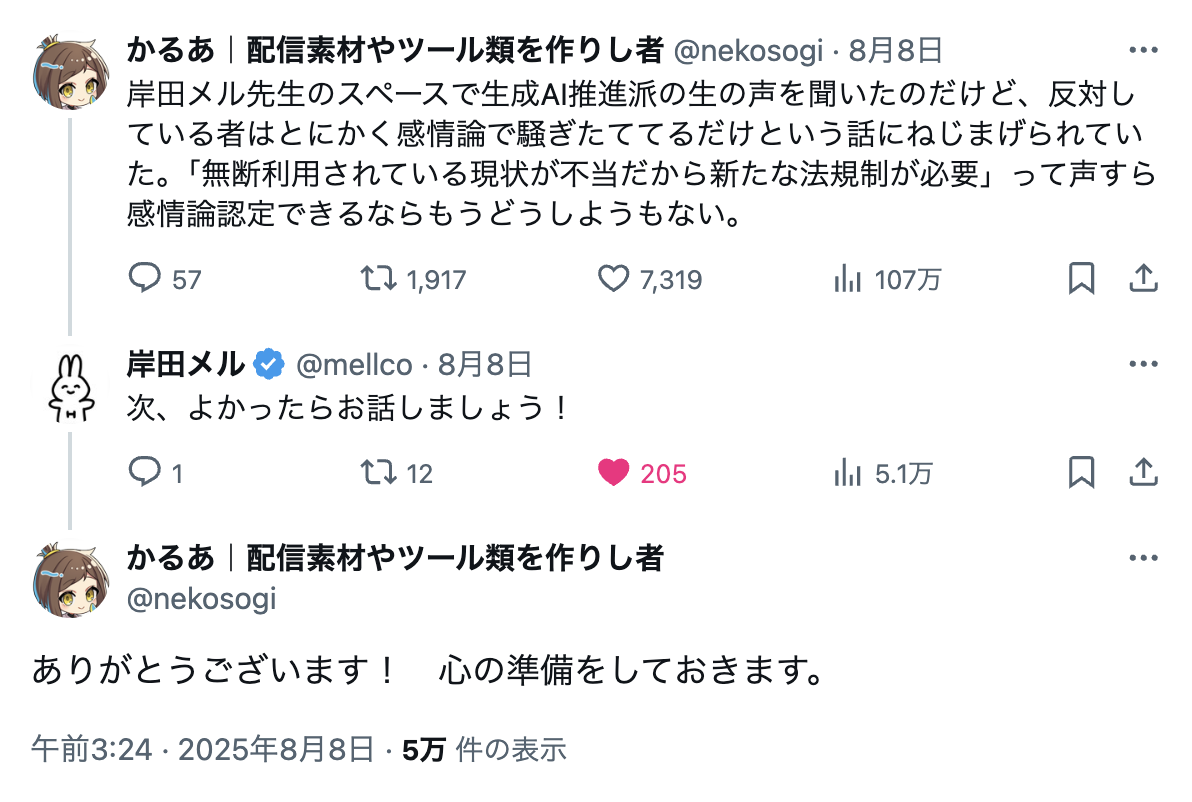
Stable Diffusion・Midjourney・NovelAIをはじめ多くの画像生成AIの基礎データセットとして利用されているLAIONは、海外の無断転載サイトDanbooruから情報を収集しています。海賊版がデータセットに含まれている形ですね。
生成AIそのものにおいても、「AI学習の場面でも、海賊版による権利侵害を助長することがないようにする必要があります。」「AI開発等を行う事業者が、海賊版等と知りながら学習データの収集を行った場合、開発された生成AIによる著作権侵害の責任を問われる可能性があります。」と文化庁は言及しており、著作権法第30条の4ではカバーされない著作権侵害=著作者への被害・損害と言えます。
また、LAIONのデータ中には児童ポルノが含まれていることもわかっており、イラストだけでなく写真の出力においても問題を抱えていますが、僕のしゃべりたいことからはズレるので今回は触れません。
前提として。特定の作家を名指しで狙い撃ちした追加学習、いわゆるLoRAはアウトという共通認識があると思っています。事業者は非享受目的の要件を満たせず、利用者が生成したものには類似性・依拠性が認められる。
では追加学習を行なっていないのならば問題がないかと言うと、先日「プロンプト中に名前を入力することで作家の模倣ができる」というケースがありました。
AIに詳しい方々からのお力添えにより
— R3 (@Ransu_33) June 29, 2025
竹輪アイ氏の生成AI画像の完全な再現に成功しました。問題を指摘した画像全てから私のアーティスト名の入ったプロンプトが検出されました。
1枚目が竹輪アイ氏の出力画像
2枚目がプロンプトを解析し再現した画像
3枚目がアーティスト名だけを消して出力した画像 pic.twitter.com/GCyRILdBSn
事実として狙い撃ちLoRAと同様のことが追加学習なしでできるのであれば、元のサービス自体も享受目的であると言え、著作権法第30条の4が適用されないものだと僕は考えています。また、利用者が模倣する目的で特定の作家名をプロンプトに打ち込んでいるため生成物に依拠性も認められます。著作権侵害にあたります。
類似性・依拠性のある著作権侵害コンテンツも、言ってしまえば海賊版と同義です。それが容易に量産できる環境があらかじめ用意されている現状は、明確に著作者の不利益と言えるでしょう。
まず事業者に対しては、
を求めるべきだと思っています。海賊版は許されていないので当然のことかと。
そして利用者に対しては、
をすればいいと思っています。依拠性がないことを証明する施策ですね。
これの何がいいって、既存の生成AIユーザー自身はほぼほぼ不利益を被っていないことなんですよね。今まで通りイラストを出力して、必要なテキストを添えるだけ。さすがにこの程度を面倒くさいと嫌がる人はいないだろうし、いたとて感情論です。
より踏み込んだ対策として著作者自身が学習を拒否できる制度作り(実際に被害が発生する前に手を打てる)もした方がいいとは思いますが、先に挙げた問題の解決にあたっては以上の4点が重要だと感じています。
人工知能関連技術の研究開発及び活用の推進に関する法律、いわゆるAI新法には、「第十三条 国は、人工知能関連技術の研究開発及び活用の適正な実施を図るため、国際的な規範の趣旨に即した指針の整備その他の必要な施策を講ずるものとする。」とあります。
日本だけが好き勝手するのはよくないよね、と新設された法律ではっきり言われてるんですよね。
なので国際社会と足並みを揃え、積極的にルール作りをしていこう!
多くの画像生成AIが生態系を確立できていない点。生成AIは性能向上のため無尽蔵に学習元のデータを求めるが、その学習元のデータプールを増やすことをしない。枯渇したら立ち行かなくなるのに。はやりの言葉を使えば持続可能性がない。サイクルが破綻している欠陥を抱えた技術に思える。
あとガイドライン違反のウマ娘R18イラストを生成して遊んでる界隈が存在してます。「ウマ45」「🐴45」でTwitterアカウント検索から辿れば出てくるかと。えっちなイラスト探してたらでくわしました。